Redis Sorted Set으로 매칭(추천) 성능 최적화하기
개요
제가 다니는 회사는 프리랜서와 고객을 매칭해 주는 서비스입니다.
고객이 업무를 요청하면 해당 업무에 적합한 프리랜서를 찾아 매칭해 주는 방식으로 서비스가 동작합니다.
저희 서비스는 특정 시간대(11:00~13:00, 15:00~17:00)에 트래픽이 집중되는 피크 타임형 서비스입니다.
이 시간대에는 전체 시스템 트래픽이 약 100 TPS 까지 증가하며, 핵심 기능인 프리랜서 추천 로직에도 많은 요청이 몰립니다.
기존 추천 로직은 DB 기반으로 동작하고 있었는데, 트래픽이 증가하면서 DB 조회 부하와 응답 지연 문제가 발생했습니다.
이를 해결하기 위해 Redis Sorted Set과 사전 계산 전략을 도입한 과정을 정리했습니다.
문제 상황: 피크 타임에 집중되는 추천 조회
전체 트래픽이 모두 추천 로직으로 향하는 것은 아니지만
추천 요청이 전체 트래픽의 30%라고 가정하면 다음과 같은 상황이 발생합니다.
30 TPS × 3600 sec × 4 hours = 432,000
즉, 피크 타임 동안 약 432,000번의 추천 조회 요청이 발생합니다.
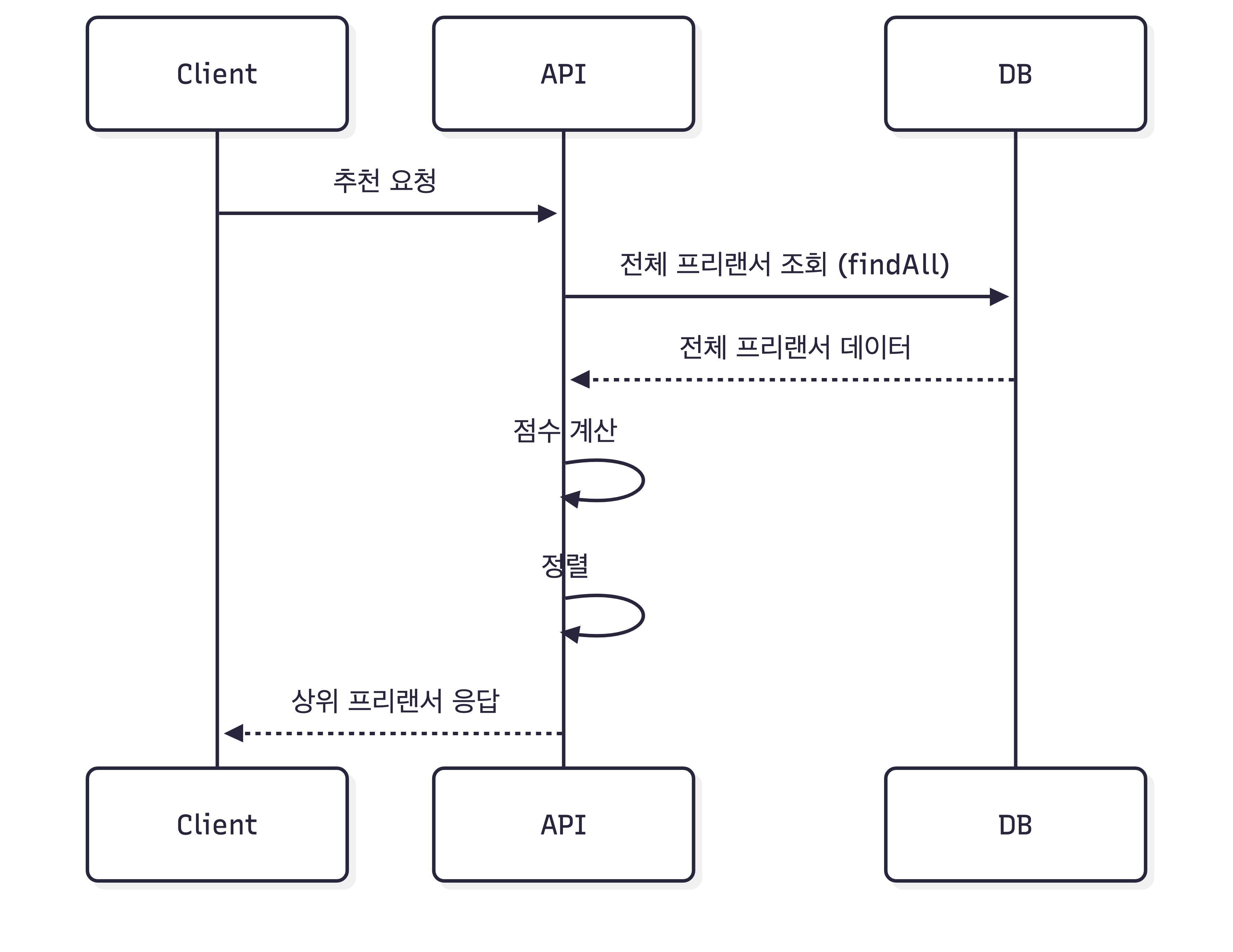
기존 추천 로직은 다음과 같은 방식이었습니다.
- DB에서 전체 프리랜서 조회 (
findAll) - 애플리케이션에서 점수 계산
- 점수 기반 정렬
- 상위 프리랜서 추천
이 구조에서는 요청이 발생할 때마다 전체 데이터를 조회해야 했습니다.
즉, 요청 발생 → 전체 프리랜서 조회 → 점수 계산 → 정렬 → 상위 후보 추출
이 과정에서 다음과 같은 문제가 발생했습니다.
- DB Full Table Scan 발생
- 애플리케이션 CPU 연산 증가
- 정렬 비용 증가
- 데이터 증가에 따른 성능 저하
특히 추천 로직이 DB 자원을 많이 사용하면서 결제나 회원 서비스 같은 다른 기능에도 성능 영향을 주는 상황이 발생했습니다.
왜 Redis를 선택했는가?
추천 로직을 최적화하기 위해 가장 먼저 고민했던 것은 추천 데이터를 어디에서 서빙할 것인가였습니다.
초기에는 DB에서 ORDER BY와 LIMIT을 이용해 상위 프리랜서를 조회하는 방식을 고려했습니다.
하지만 피크 타임에 트래픽이 집중되는 환경에서는 매 요청마다 정렬 연산이 발생하게 되고
이는 CPU와 디스크 I/O를 크게 사용하는 구조였습니다.
특히 추천 로직은 전체 프리랜서를 대상으로 점수를 계산하고 정렬해야 하는 특성이 있기 때문에
데이터가 증가할수록 DB 부하는 선형적으로 증가하는 구조였습니다.
이 문제를 해결하기 위해 메모리 기반 데이터 저장소인 Redis를 도입했습니다.
Redis는 다음과 같은 장점이 있습니다.
- 메모리 기반 조회 성능
- 빠른 데이터 접근 속도
- 다양한 자료구조 제공
특히 Redis의 Sorted Set(ZSET) 자료구조는 score 기반으로 자동 정렬되는 구조이기 때문에
추천 시스템 구현에 매우 적합했습니다.
왜 findAll() 캐싱을 선택하지 않았는가?
처음에는 findAll() 결과를 캐싱하는 방법도 고려했습니다.
예를 들어 전체 프리랜서 데이터를 캐시에 저장하고
추천 요청이 들어올 때 캐시 데이터를 기반으로 점수를 계산하는 방식입니다.
하지만 이 방식에는 몇 가지 문제가 있었습니다.
1. 첫 번째는 연산 비용 문제입니다.
추천 점수는 리뷰 수, 등급, 활동량 등 다양한 요소를 기반으로 계산되기 때문에
매 요청마다 다음과 같은 연산이 필요했습니다.
캐시에서 전체 데이터 조회 → 점수 계산 → 정렬 → 상위 후보 추출
즉 DB 조회는 줄일 수 있지만 추천 로직의 O(N) 연산 자체는 여전히 남게 됩니다.
2. 두 번째는 캐시 데이터 크기 문제입니다.
전체 프리랜서를 캐시에 저장하면 캐시 메모리 사용량이 계속 증가하게 됩니다.
결국 이 방식은 DB 부하를 줄일 수는 있지만 추천 로직의 연산 병목 자체를 해결하지는 못하는 구조였습니다.
상위 추천 후보만 관리하는 전략
추천 시스템에서 실제로 필요한 데이터는 전체 프리랜서 목록이 아니라 상위 추천 후보군입니다.
서비스 특성상 한 번의 매칭에서 수천 명의 프리랜서를 추천할 필요는 없습니다.
일반적으로 추천 결과는 상위 수십 명에서 수백 명 정도의 후보군이면 충분합니다.
따라서 전체 프리랜서를 캐싱하는 대신
상위 추천 후보군만 Redis에 유지하는 전략을 선택했습니다.
추천 시스템에서는
전체 데이터를 관리하는 것보다 필요한 상위 데이터를 빠르게 조회하는 것이 더 중요합니다.
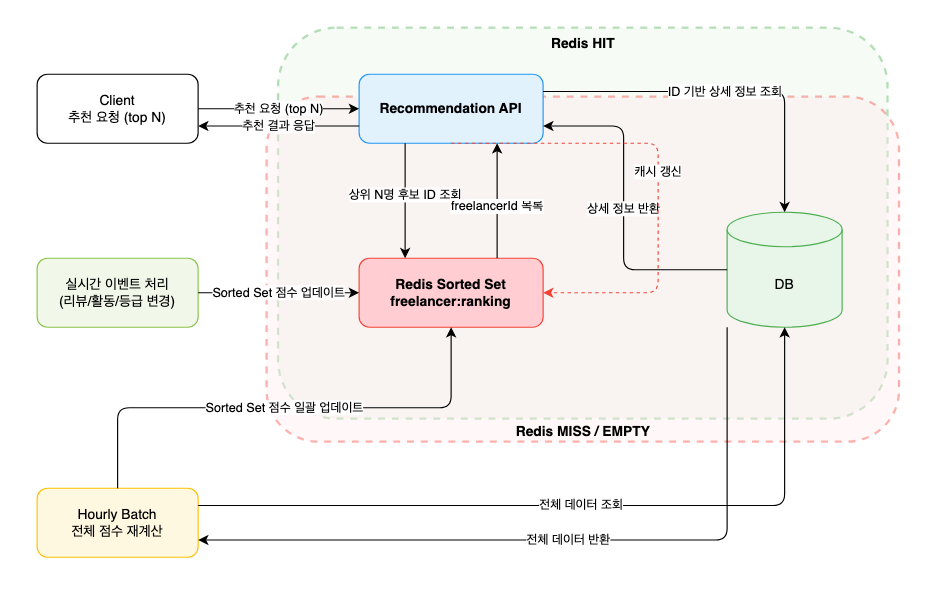
해결 전략: 사전 계산 + Redis Sorted Set
Redis 도입 후 구조
Redis Sorted Set (ZSET) 활용
Redis Sorted Set은 score 기반으로 자동 정렬되는 자료구조입니다.
프리랜서의 종합 점수(리뷰, 등급, 활동량 등)를 미리 계산하여
Redis ZSET에 저장하도록 설계했습니다.
ZADD freelancer:ranking score freelancerId
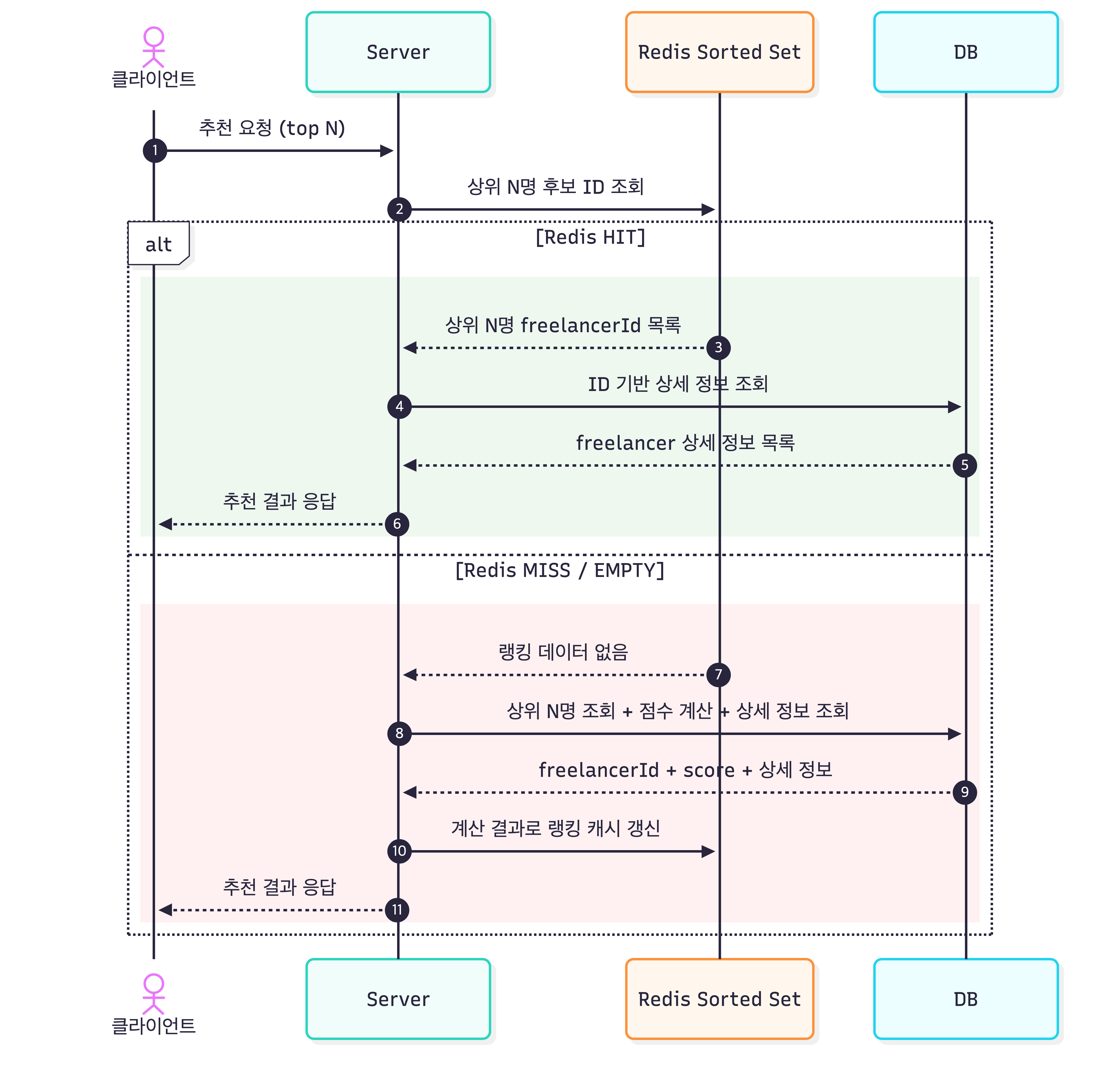
이제 추천 요청이 들어오면 요청 수(N)에 맞춰 상위 후보를 조회합니다.
1
2
점수가 높은 순으로 상위 N명 조회
ZREVRANGE freelancer:ranking 0 (N-1)
Sorted Set 조회의 시간 복잡도는 O(log(N) + M)으로 DB Full Scan 대비 훨씬 효율적인 성능을 제공합니다.
다만 운영 환경에서는 항상 ZSET 데이터가 존재한다고 가정할 수 없습니다. 배포 직후, Redis 재시작 직후, 또는 초기 구간(콜드 스타트)에는 순위 데이터가 비어 있을 수 있기 때문입니다.
그래서 추천 조회 로직을 다음과 같이 구성했습니다.
1
2
3
4
1) Redis ZSET 조회 (ZREVRANGE 0 ~ N-1)
2) 결과가 비어 있으면 DB 직접 조회 + 점수 계산
3) 계산 결과를 Redis ZSET에 재적재 (ZADD)
4) 사용자에게 추천 결과 응답
즉, 첫 요청이나 캐시 미스 상황에서는 DB가 안전망 역할을 수행하고, 이후 요청부터는 Redis에서 빠르게 상위 후보를 반환하는 구조입니다.
하이브리드 업데이트 전략
추천 점수는 지속적으로 변하는 값이기 때문에
다음과 같은 하이브리드 업데이트 전략을 적용했습니다.
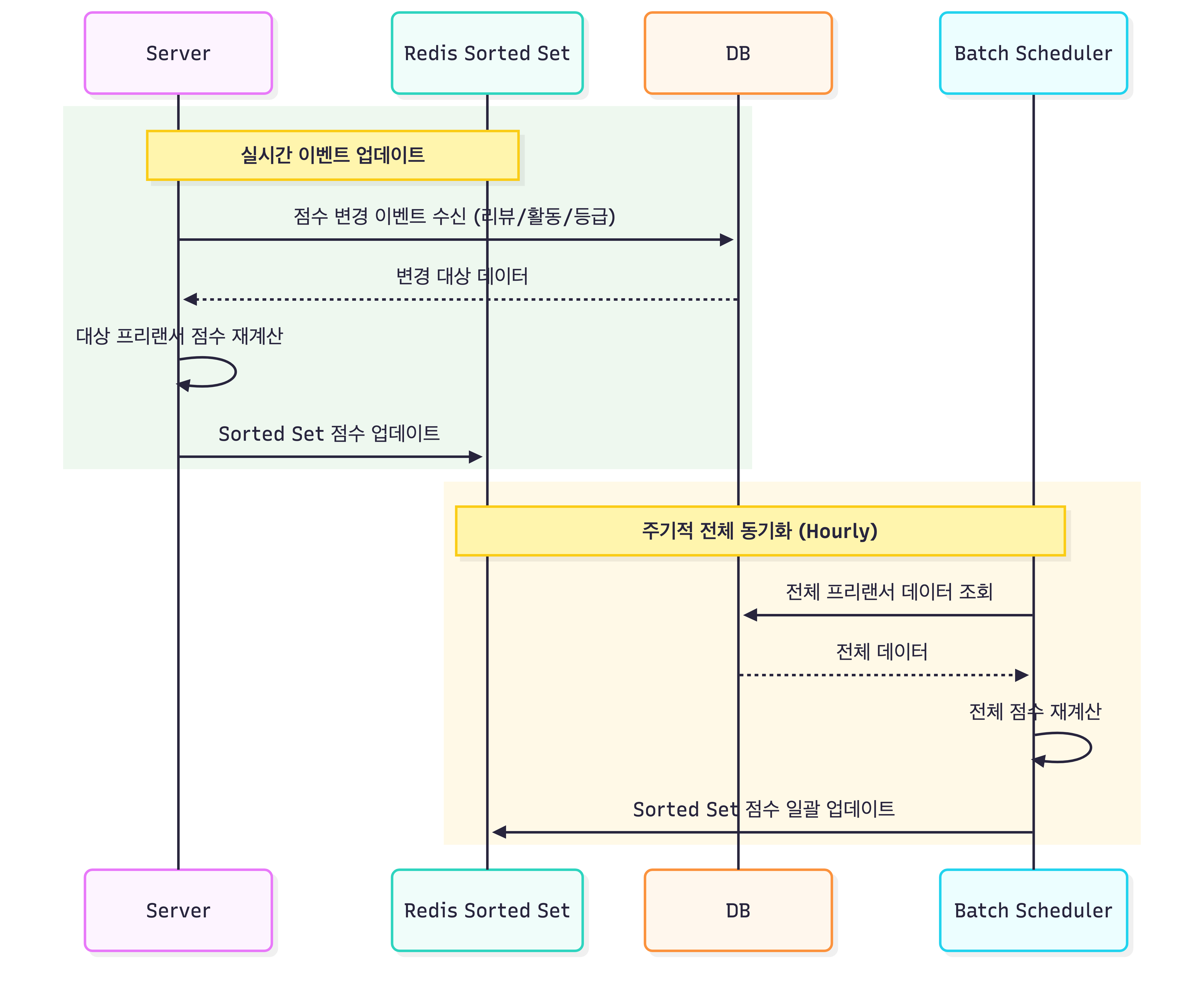
실시간 이벤트 업데이트
리뷰 작성이나 활동 증가 같은 이벤트가 발생하면
@TransactionalEventListener를 통해 Redis 점수를 즉시 업데이트합니다.
주기적 전체 동기화 (Hourly Sync)
매시간 전체 점수를 재계산하여 Redis 데이터를 갱신합니다.
배치는 1시간에 1회 실행되기 때문에 하루 기준 총 24회 수행됩니다.
따라서 기존처럼 요청마다 DB를 조회하는 구조가 아니라
하루 24번의 배치 작업만 DB 전체 데이터를 조회하도록 변경되었습니다.
1시간인 이유
추천 점수는 실시간 정확도가 절대적으로 중요한 데이터가 아니기 때문에
1시간 단위의 Eventual Consistency 모델을 선택했습니다.
이 과정은 다음 문제를 해결하기 위한 설계입니다.
Redis 장애 대응 전략 (Fallback)
Redis는 인메모리 시스템이기 때문에 장애 가능성도 고려해야 합니다.
따라서 Redis 장애 발생 시 DB 기반 추천 로직으로 fallback 되도록 설계했습니다.
이 경우 DB 부하는 증가할 수 있지만
- 서비스 완전 중단 방지
- 핵심 기능 지속 제공
이라는 관점에서 방어적 설계 를 적용했습니다.
최종 아키텍처
수치로 보는 개선 효과
이번 최적화의 핵심은
매 요청마다 반복되던 연산을 사전 계산 방식으로 전환한 것
입니다.
DB 조회 부하 감소
| 구분 | Full Scan 횟수 |
|---|---|
| 기존 | 약 432,000 |
| 개선 | 하루 24회 (Hourly Sync 배치 기준) |
즉 DB 전체 탐색 횟수를 약 18,000배 감소시킬 수 있었습니다.
연산 병목 제거
기존 방식
요청 발생 → DB 조회 → 점수 계산 → 정렬 → 응답
개선 방식
배치에서 점수 계산 → Redis 저장 → 요청 시 바로 조회
이 구조를 통해 추천 API 요청 시 연산 비용이 거의 발생하지 않게 되었습니다.
마치며
이번 프로젝트를 통해 단순히 기능을 구현하는 것과
고부하 환경에서도 안정적으로 동작하는 시스템을 설계하는 것의 차이를 체감할 수 있었습니다.
특히 다음 세 가지 관점을 깊이 고민해 볼 수 있었습니다.
- 특정 로직이 전체 시스템 자원을 점유하지 않도록 하는 성능 격리
- 정확성과 성능 사이에서 선택해야 하는 의도적인 트레이드오프
- 장애 상황에서도 서비스가 동작하도록 하는 Fallback 설계
이번 경험을 통해 사전 계산 전략과 Redis 자료구조를 활용한 성능 최적화의 중요성을 다시 한번 이해할 수 있었습니다.