배포 없이 실험을 통제하는 Feature Flag 플랫폼 구축기: A/B 테스트, 장애 대응, 점진 배포까지
개요
그로스팀에 합류한 뒤 가장 먼저 부딪힌 문제는
“실험을 하려면 왜 매번 배포가 필요하지?” 였습니다.
A/B 테스트는 빠르게 가설을 검증해야 하는데, 기능 on/off, 트래픽 비율 변경, 타깃 조건 수정 같은 작업이 배포 파이프라인에 묶여 있으면
실험 속도가 급격히 느려집니다.
그래서 운영 배포 없이 제어 가능한 Feature Flag 기능을 처음부터 직접 만들었습니다.
단순 실험 도구를 넘어, 장애 대응과 점진 배포까지 포함하는 운영 제어 레이어를 목표로 했습니다. 또한 그로스 마케터와 프로덕트 오너가 개발자 도움 없이도 실험 조건과 노출 비율을 직접 조절할 수 있는 운영 환경이 필요했습니다.
구현 요구사항
1) 배포 없이 기능 on/off 제어
운영 중에도 백오피스에서 플래그를 즉시 변경해 실험을 시작/중단할 수 있어야 했습니다.
2) 장애 시 특정 기능만 즉시 차단
전체 롤백 대신 문제 기능만 끌 수 있어야 장애 전파를 막을 수 있습니다.
즉, Feature Flag는 실험 도구이기도 하지만 운영 안전장치(kill switch) 이기도 했습니다.
3) 점진 배포 (Progressive Rollout)
1% -> 10% -> 30% -> 100%로 점진 확장하면서 리스크를 통제해야 했습니다.
왜 직접 구축했는가
Feature Flag 도입을 검토할 때 기존 솔루션도 함께 살펴봤습니다.
- LaunchDarkly / GrowthBook (SaaS): 기능은 충분하지만 사용자 식별 데이터가 외부로 나가는 구조였고, 비용 문제도 있었습니다.
- Unleash (오픈소스): 별도 서버를 띄워야 하고, 운영 인프라가 하나 더 늘어나는 부담이 있었습니다.
- FF4J / Togglz (Java 라이브러리): 단순 on/off 수준에는 맞지만, 해시 기반 점진 배포나 플래그 성격별 Fail-Open/Fail-Close 같은 커스텀 정책을 얹으려면 어차피 상당 부분을 직접 구현해야 했습니다.
외부 솔루션은 범용적으로 만들어져 있어서, 우리 서비스에 맞는 캐시 전략과 Fallback 정책을 직접 제어하기 어렵습니다.
추가 인프라 없이 기존 스택 안에서 원하는 동작을 정확히 구현하는 게 더 현실적인 선택이었습니다.
구현
아래 코드는 실제 회사 코드와 다르며, 핵심 흐름을 이해하기 쉽게 재구성한 예시입니다.
1단계: 퍼센트 기반 점진 배포
가장 먼저 유저를 일정 비율로 나눠 플래그를 활성화하는 로직을 구현했습니다.
flagKey + userId를 조합해 해시한 버킷 번호로 같은 유저는 항상 같은 결과를 받도록 했습니다.
1
2
3
4
5
6
7
8
public boolean isEnabled(String flagKey, UserContext ctx) {
FlagConfig config = getConfig(flagKey);
if (!config.isActive()) return false;
// userId 기반 해시로 일관된 버킷 배정 (같은 유저는 항상 같은 결과)
int bucket = Math.abs(hash(flagKey + ctx.getUserId())) % 100;
return bucket < config.getRolloutPercent(); // e.g. 10 → 하위 10%만 활성화
}
2단계: DB 기반으로 전환
그런데 문제가 생겼습니다.
퍼센트 값이 코드에 박혀 있으면 1% → 10%로 바꿀 때마다 배포가 필요했습니다.
여러 서버 인스턴스가 떠 있는 환경에서는 인스턴스마다 반영 시점도 달랐습니다.
그래서 퍼센트 값을 DB에 저장하고 백오피스에서 직접 변경할 수 있도록 했습니다.
배포 없이 즉시 반영이 가능해졌지만, 새로운 의문이 생겼습니다.
3단계: 로컬 캐시 도입
Feature Flag는 모든 API 요청마다 호출되는 구조였습니다.
매 요청마다 DB를 조회하면 DB에 부하가 생기고, 응답 지연으로 이어질 수 있었습니다.
그래서 인스턴스 내 로컬 캐시(Caffeine) 를 도입해 DB 조회를 최소화했습니다.
1
2
3
4
5
6
public FlagDecision decide(String flagKey, UserContext ctx) {
FlagConfig config = l1Cache.get(flagKey, k -> dbRepository.find(k)
.orElseGet(() -> defaultPolicy.get(k)));
return evaluator.evaluate(config, ctx);
}
왜 Caffeine인가
로컬 캐시 라이브러리 선택에서 Caffeine을 고른 이유는 명확했습니다.
- 네트워크 없음: Redis와 달리 인스턴스 내에서 처리되므로 조회 지연이 거의 없음
- W-TinyLFU 알고리즘: Guava Cache 대비 캐시 히트율이 높고 메모리 효율이 좋음
- TTL / 만료 정책 내장: 별도 구현 없이 오래된 캐시 자동 만료 적용 가능
- Spring 통합 용이:
spring-boot-starter-cache와 바로 연동되어 설정 부담이 낮음 - 읽기 빈번 + 변경 드문 데이터에 최적: A/B 실험 설정의 접근 패턴과 딱 맞는 구조
다만 캐시가 갱신 이벤트를 놓치면 오래된 값이 계속 남을 수 있습니다.
이를 대비해 Pub/Sub만 믿지 않고 TTL을 함께 적용해 자동 만료를 보장했습니다.
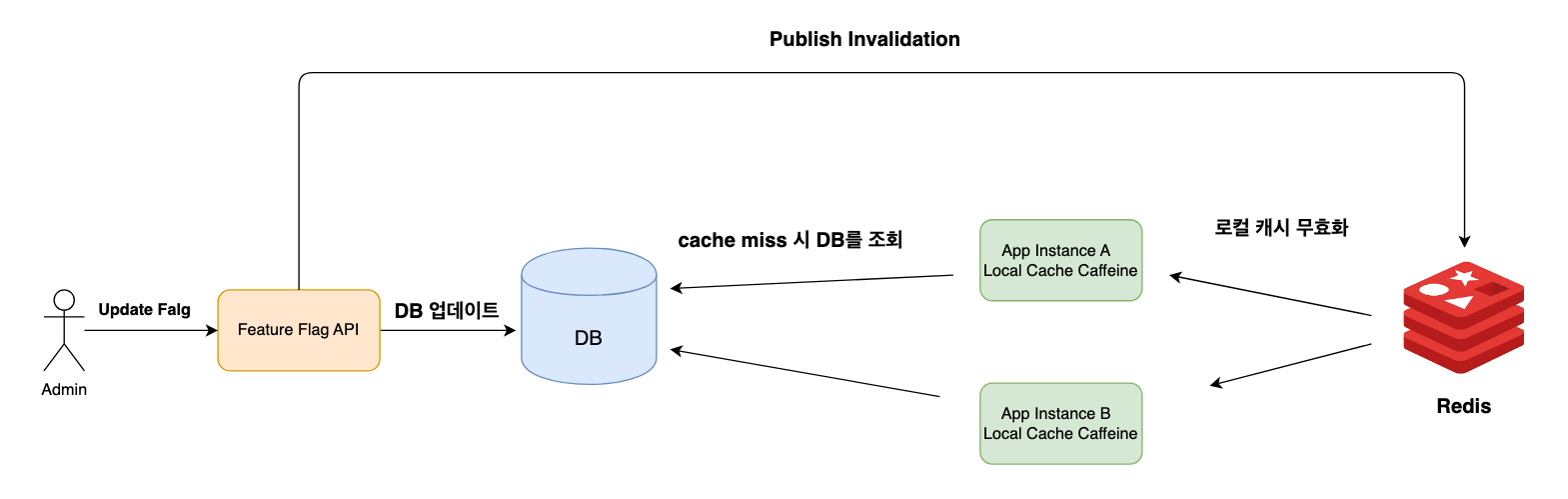
4단계: 멀티 인스턴스 정합성 문제
로컬 캐시를 쓰니 새로운 문제가 생겼습니다.
백오피스에서 플래그를 바꿔도 각 인스턴스의 캐시가 남아 있으면 변경이 반영되지 않았습니다.
그래서 Redis Pub/Sub로 무효화 이벤트를 전파하는 구조를 추가했습니다.
플래그가 변경되면 모든 인스턴스가 해당 키를 로컬 캐시에서 즉시 제거하고,
다음 요청부터 최신값을 DB에서 재조회합니다.
어떤 선택을 했는가 (Trade-off)
Fail-Open / Fail-Close 분리
플래그 판별 중 오류가 발생했을 때 “켜진 채로 실패할 것인가, 꺼진 채로 실패할 것인가”를 플래그 성격에 따라 다르게 가져갔습니다.
- 실험용 플래그(A/B):
Fail-Open
오류가 나도 서비스는 그대로 켜둡니다. 실험이 잠깐 이상해지더라도 서비스 자체가 멈추는 것보다 낫기 때문입니다. - 안전/차단용 플래그(Kill Switch):
Fail-Close
오류가 나면 일단 기능을 꺼버립니다. 꺼야 하는 상황인지 모를 때 켜놨다가 장애가 퍼지면 더 크기 때문입니다.
Fallback 정책
- 1순위: L1 마지막 정상값
- 2순위: DB 재조회
- 3순위: 코드 기본값(플래그별 안전 기본값) + 알람
성과
- 실험 시작/종료 리드타임: 배포 단위 -> 백오피스 즉시 반영
- 장애 대응: 전체 롤백 없이 문제 기능만 즉시 차단
- 점진 배포: 트래픽 비율 단계적 확대로 리스크 감소
- 팀 협업: 개발/기획/데이터팀이 같은 제어면을 공유
마치며
Feature Flag는 “if문 하나 더”가 아니라
실험 속도와 운영 안정성을 동시에 끌어올리는 제어 시스템이었습니다.
그로스팀에서 처음으로 Feature Flag를 직접 구현해보면서, 단순한 기능 개발과는 다른 고민을 많이 했습니다.
기능을 만드는 것보다 어떤 상황에서 어떻게 동작할지를 미리 정의하는 것이 더 중요했고, 그게 운영 안정성의 핵심이었습니다.
그로스팀 특성상 빠른 실험이 중요한 환경이었기에, 이 구조가 실험 속도와 안정성을 동시에 잡는 기반이 됐습니다.